
RAG, kort voor retrieval augmented generation, is bijna onlosmakelijk verbonden met het gebruik van generatieve AI op de werkvloer. Wat is RAG, en waarom is het zo’n essentieel onderdeel van een nuttige AI-implementatie?
Een generatieve AI-assistent zonder retrieval augmented generation (RAG) is als een enthousiaste digitale stagiair met een pleaser-attitude. Vraag je iets aan die assistent, dan zal hij zijn uiterste best doen om een antwoord te geven, ook wanneer hij het antwoord niet kent.
Generatieve AI gecombineerd met RAG is als diezelfde ijverige stagiair, die deze keer gewapend is met een encyclopedie gevuld met relevante kennis. Stel je dezelfde vraag, waarvoor de parate kennis ontoereikend is, dan zal de stagiair te rade gaan in de encyclopedie op zoek naar het echte antwoord.
In het eerste geval spreken we bij generatieve AI van een hallucinatie: je krijgt een antwoord dat juist klinkt, maar het niet is. In het tweede scenario heeft de AI-assistent RAG gebruikt om via de juiste informatie tot een echt antwoord te komen.
Waarom is RAG noodzakelijk?
Generatieve AI is gebouwd op Large Language Models (LLM’s). LLM’s zijn modellen zoals GPT 4.5 van OpenAI, of Llama 3.3 van Meta. Ze werden ontwikkeld door voornamelijk Amerikaanse technologiereuzen en getraind op enorme AI-supercomputers. Training van een LLM gebeurt aan de hand van trainingsdata. Door een neuraal netwerk immens veel geannoteerde data te voederen, ontstaan er verbindingen tussen digitale neuronen waardoor het netwerk na verloop van tijd in staat is om correct te reageren op nieuwe data.
Toon zo’n neuraal netwerk duizenden foto’s van katten en honden, en na verloop van tijd kan het de dieren zelf herkennen op nieuwe beelden. Je kan het zoals OpenAI ook grootser zien en het halve internet aan artikels, posts op fora, digitale boeken, blogs en meer als trainingsdata inzetten. Train een netwerk met data op schaal, en je krijgt een model dat ChatGPT mogelijk maakt.
LLM’s zijn getraind aan de hand van dergelijke immense hoeveelheden algemene en historische data. Op basis van die data zijn ze in staat antwoorden te formuleren op vragen, die heel realistisch klinken. Alleen: zodra een model als GPT 4.5 wordt gefinaliseerd, is de training voorbij. Denk aan een student die z’n diploma haalt en aan de slag gaat. De lessen zijn voorbij, dus extra (nieuwe) informatie zal niet meer gekoppeld worden aan de student en het diploma.
De student gaat aan de slag met de kennis die hij heeft opgedaan bij het afstuderen. Op dezelfde manier gaat het LLM aan de bak met de kennis die het heeft opgedaan tijdens de training. Een getraind neuraal netwerk gebruiken, heet inferentie. In de inferentiefase heeft het LLM geen weet meer van data die na het finaliseren worden aangemaakt. Een LLM kan bijgevolg uit zichzelf geen actualiteitsvragen beantwoorden.
- Een LLM wordt getraind op een veelvoud van algemene data, en heeft geen kennis van bedrijfsspecifieke gegevens, of informatie die geen deel uitmaakte van het trainingsproces.
Trainen met je eigen data
OpenAI, Meta, Microsoft en andere partijen hebben als het goed is geen toegang tot jouw specifieke bedrijfsdata. Een LLM is bijgevolg niet getraind op die data. Vraag je een beschrijving van product X of informatie over klant Y, dan zegt het LLM in het beste geval dat het die kennis niet heeft, of hallucineert het in het slechtste geval een goed klinkend antwoord.
Om een LLM in een bedrijfscontext in te zetten, moet het model wel kennis hebben van alle belangrijke data in je bedrijf. Denk aan de productcatalogus, de klanten, de financiële resultaten en meer. Je kan het model daarvoor finetunen.
Finetunen is als een extra opleiding van de stagiair op de job zelf. Je traint het model in dat geval verder. Alleen: dat vereist opnieuw dure AI-rekenkracht en de nodige kennis. Het duurt lang en kost veel geld. Opnieuw zal je het model op een bepaald moment finaliseren. Twee dagen later lanceer je misschien een nieuw product of strik je een nieuwe klant, en kan je opnieuw beginnen.
Finetuning is relevant om generatieve AI-modellen achtergrondkennis te geven over je bedrijf, maar het lost de basis van het probleem niet op. Je kan nog steeds geen vraag stellen, met de garantie dat je een juist en actueel antwoord krijgt.
- Modellen bijtrainen op je data of finetunen is een complex en duur proces, en lost het probleem niet op: nieuwe en veranderde data die geen deel uitmaakten van de training, kent het LLM niet.
Retrieval Augmented Generation
RAG gooit het over een andere boeg. RAG verwijst naar een methode waar het LLM niet verder wordt uitgebreid, maar wel de vraag die je stelt. Wil je iets weten over de producten van je organisatie, dan stel je gewoon de vraag: ‘Wat is het verschil tussen product X en Y’.
Voor die vraag naar het LLM gaat, schiet RAG in actie. Een ander algoritme ziet aan de prompt dat je vraag over producten gaat. Dat algoritme koppelt nu je vraag aan de productcatalogus en prijslijst van je onderneming. Pas dan wordt de vraag doorgezet aan het LLM.
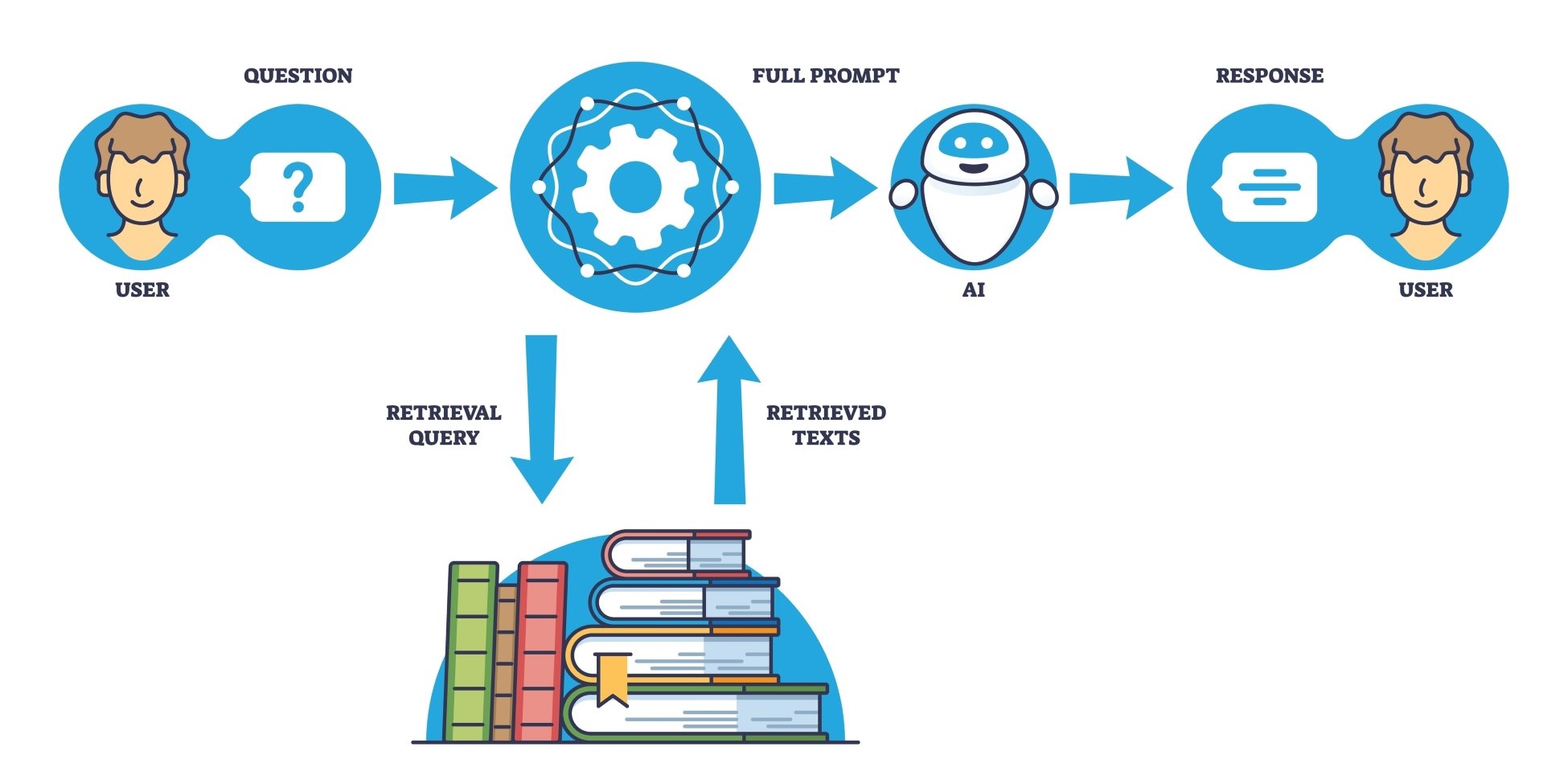
Het LLM gaat nu specifiek op zoek naar een antwoord in al jouw data. Het IQ van de AI-assistent is het product van de algemene training, maar het antwoord op je specifieke vraag komt uit de meegeleverde data.
Die databronnen zijn niet statisch. Bij iedere prompt worden ze opnieuw bijgevoegd. Je kan databases linken, maar ook wiki’s vol met tekst, mails, facturen, noem maar op. Je actuele bedrijfsdata worden telkens aan de vraag gekoppeld, waardoor het LLM wel steeds toegang heeft tot correcte en recente informatie.
Voor jou duurt het even om een productcatalogus van 2.000 bladzijden te lezen, te linken aan prijslijsten en de evoluties daarvan, en op zoek te gaan naar de klanten die betrokken zijn. Voor een LLM is zoiets een werk van seconden. Met RAG rijk je de informatie aan. Het LLM neemt die in zich op, en formuleert een antwoord. Het antwoord wordt gegenereerd, nadat het geaugmenteerd is met opgehaalde data uit de bedrijfssystemen.
- Met RAG komen de capaciteiten van het LLM van de training, maar de kennis komt van relevante data uit actuele bronnen, die op een slimme manier wordt bijgevoegd bij een prompt.
Praktisch
RAG vereist geen dure training van een LLM. Sterker nog: RAG kan je implementeren met enkele lijnen code. Aanbieders van AI-oplossingen kunnen dat voor hun rekening nemen. Het is aan jou om je data op orde te krijgen. Net als alle AI-toepassingen werkt RAG alleen maar goed als de brondata kwalitatief is.
Wanneer het RAG-systeem toegang heeft tot je bedrijfsdata, verwerkt het die in een vectordatabase. Dat is een continu proces. Wanneer je dan een prompt voorschotelt aan het LLM, gaat het RAG-systeem daar via de vectordatabase relevante data aan koppelen.
De koppeling van de data is geen intensief proces. Je hebt er geen waanzinnige HPC-systemen voor nodig en het kost geen handenvol geld. Je koppelt de kennis die je hebt, aan het AI-brein dat je in huis hebt gehaald, en geniet meteen van de resultaten.
Het is wel belangrijk dat je data en de AI-oplossing vlot gekoppeld zijn. Het kan bijvoorbeeld helpen om data in de cloud te bewaren wanneer je een AI-oplossing in de cloud gebruikt, of de inferentie naar lokale servers te halen wanneer je gegevens on-premises staan.
- RAG is eenvoudig te implementeren en zorgt voor AI-antwoorden op maat, zonder dat daar grote trainingskosten mee gepaard gaan.
Lezen en leren
We kijken opnieuw naar onze analogie van de stagiair in het begin. Het RAG-systeem is een soort assistent die naast de stagiair zit, en weet waar alle belangrijke data ongeveer staan. Wanneer jij een vraag stelt, fluistert de assistent in het oor van de stagiair welke databases, wiki’s en andere systemen relevant zijn voor die vraag. De stagiair is dezelfde als in het begin, maar het antwoord is plots uniek en waardevol.
Hoe RAG-systemen precies werken, hangt af van implementaties. Ontwikkelaars zoeken steeds naar nieuwe systemen om data nauwkeuriger, sneller en gerichter aan prompts toe te voegen. De essentie blijft wel dezelfde: met RAG kan je een basis-LLM inzetten om nauwkeurige en persoonlijke antwoorden te generen op basis van je eigen data.
RAG maakt het mogelijk om in natuurlijke taal te praten met je data. De training van het LLM zorgt voor de capaciteiten ervan, jouw data voor de eigenlijke kennis. Dat maakt een LLM gecombineerd met RAG zo krachtig.
Aanbieders
Retrieval augmented generation is een onderdeel van de oplossingen van heel wat AI-fabrikanten. AI-specialist Nvidia laat ontwikkelaars bijvoorbeeld toe RAG te implementeren via de NeMo Retriever, die onderdeel is van de AI-stack van het bedrijf.
Snowflake, dat data van klanten in een cloudplatform vergaard, beveiligd en toegankelijk maakt, heeft RAG ook geïmplementeerd in zijn AI-oplossingen. Daar kunnen gebruikers hun data via Cortex AI koppelen aan een LLM naar keuze. Snowflake van zijn kant zet in op het RAG-aspect, om op die manier zo efficiënt mogelijk de juiste data te koppelen aan een prompt.
Cloudera verdient ook vermelding, met een zijn RAG Studio. Die laat gebruikers toe chatbots te bouwen die via RAG aan hun actuele data worden gekoppeld.
Ook voor lokale AI speelt RAG een rol. Denk daarbij aan Lenovo’s AI-assistent AI Now, de AI Companion van HP, Nvidia Chat met RTX en ook AMD laat je toe een chatbot te bouwen die uitsluitend op je computer draait. Die oplossingen laten je toe vragen te stellen aan een LLM dat lokaal draait, en voor de antwoorden kijkt naar data en bestanden in mappen op je pc. Ook dat is een vorm van (minder gerichte) RAG.