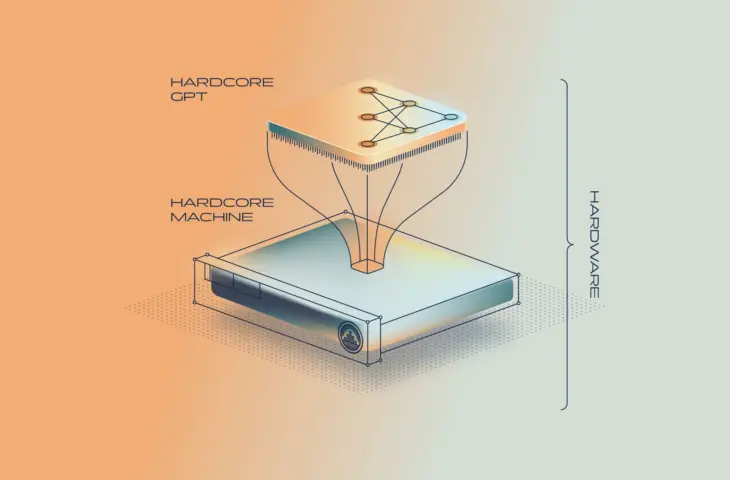
De start-up Taalas lanceert een demonstratiechip die alle bestaande AI-acceleratoren met enorme marge overtreft in snelheid. Dat kan dankzij een nieuwe en goedkopere aanpak, waarbij het AI-model mee ingebakken wordt in de hardware.
De Canadese start-up Taalas werkt zich in de belangstelling met de lancering van de Taalas HC1-demonstratiechip. Dat is een AI-accelerator voor inferentie die in een totaal andere categorie presteert dan de snelste AI-chips die vandaag op de markt zijn.
Snelheidsrecord
De HC1 verwerkt prompts aan net geen 17.000 tokens per seconde (16.960). De Nvidia B200 houdt het op 594 tokens per seconde. De meest performante AI-chip van dit moment, van Cerebras, is met 1.981 tokens per seconde nog steeds meer dan acht keer trager.

Let wel: de cijfers komen van Taalas zelf. Ze kloppen ongeveer met wat de concurrentie aangeeft, als zijn er scenario’s en modellen waarin de Nvidia B200 bijvoorbeeld sneller presteert. De grootteordes blijven wel correct. Bovendien is de Taalas HC1 aanzienlijk goedkoper. De chip met 53 miljard transistors wordt gebakken op het iets oudere TSMC 6 nm-procedé en zit niet volgestouwd met duur HBM-geheugen, zoals andere accelerators.
LLM als hardware vs. software
Dat kan omdat Taalas voor een radicaal andere aanpak kiest. Op de HC1-accelerator kan je immers geen eigen LLM’s inladen. De ingenieurs van Taalas hebben in de plaats daarvan een LLM hardwarematig ingebakken op de chip zelf. In dit demonstratiemodel gaat het om het iets oudere model Llama 3.1 8B.
Taalas merkt op dat AI-modellen vandaag software zijn, en in die hoedanigheid heel veel rekenkracht vergen. Die vaststelling komt niet uit de lucht vallen: steeds krachtigere AI-datacenters van grote AI-bedrijven zetten de beschikbare stroomtoevoer onder druk en hebben de toeleveringsketen van RAM en SSD’s extreem belast.
De investeringen voor dergelijke datacenters lopen bovendien op tot in de tientallen miljarden en meer, wat het businessmodel voor de consumptie van AI onder druk zet. Een realistisch pad naar terugverdieneffecten op de korte termijn blijft uit.
Dat moet anders, redeneren de Canadezen. Om de wereld echt te veranderen met AI, moet de efficiëntie met factor 1.000 omhoog. Dat kan volgens Taalas niet door LLM’s als software op algemene systemen te draaien. Het model moet niet gesimuleerd worden op een traditionele computer, maar de computer zelf worden.
Geen HBM nodig
Van dat idee is de Taalas HC1 een demonstratiechip. Llama 3.1 8B is niet zo’n groot model, waardoor het de voorkeur genoot voor de eerste iteratie van het concept. Het model zit bij de accelerator op hardware-niveau ingebakken, waardoor de brug tussen chip en geheugen als flessenhals wegvalt.

Daardoor heeft de Taalas HC1 geen nood aan HBM-geheugen om het LLM op in te laden, en al evenmin aan 3D-stacking of speciale I/O. De efficiëntie stijgt met factor 10 en de hittegeneratie van de chip daalt, waardoor ook vloeistofkoeling geen must is.
Taalas heeft 2,5 jaar gewerkt aan de chip met een team van 24 mensen en een budget van amper 30 miljoen dollar. Het bedrijf claimt dat het een nieuw model in twee maanden kan omzetten naar hardware op een chip op maat. Daartoe heeft het de Taalas Foundry ontwikkeld. De productiekost van de chips zou 20 keer lager liggen dan die van traditionele AI-accelerators.
Antwoord in een vingerknip
Naast een lagere kost, zowel operationeel als in productie, is de snelheid een immense troef van de Taalas HC1. Taalas heeft een online chatbot gelanceerd (chatjimmy) waarmee je dat zelf kan ervaren. Zelfs langere antwoorden van de chatbot verschijnen onmiddellijk.
Zo vroegen we om in ongeveer 300 woorden uit te leggen wat het voordeel is van een hardwarematig geoptimaliseerde AI-chip. Een antwoord van 256 woorden verscheen zodra we op Enter drukten. Taalas toont daarbij een statistiek over de snelheid: onze prompt werd aan 15.735 tok/s behandeld waardoor het antwoord in 0,031 seconden werd gegenereerd.
Daarbij verdwijnt de klassieke ervaring van chatten met een LLM, waarbij tekst voor je ogen wordt gegenereerd. Zeker langere antwoorden zie je in realtime opgesteld worden. Dat kan bij complexe prompts al snel enkele seconden of langer duren.
AI die praat
Voor een geschreven conversatie is zo’n vertraging nog niet zo’n ramp, maar Taalas kijkt verder. Heel wat AI-toepassingen vereisen wel een lage latency. Denk in eerste instantie aan gesproken conversaties. Stel je een vraag aan een AI-systeem, dan is de ervaring een stuk beter wanneer er geen pauze van vijf seconden volgt voor het antwoord.
Het is niet omdat het model ingebakken zit, dat er geen flexibiliteit meer overblijft. Zo kan je via LoRA’s (low rank adapters) parameters zoals het context window nog aanpassen. RAG (retrieval augmented generation) blijft ook mogelijk. De RAG-component kan prima als software boven op het LLM in de chip draaien.
Nadelen
Er zijn natuurlijk wel nadelen. Door het model in te bakken, is een investering in een chip onlosmakelijk verbonden aan één model. Gezien de snelle evolutie van het AI-veld, is dat een serieus minpunt. Een LLM kan vandaag hypermodern maar binnen een half jaar al verouderd zijn.
De testchip met Llama 3.1 8B is zo wel een snelheidsduivel maar geen genie. Het model met een relatief bescheiden acht miljard parameters kan niet concurreren met de grote LLM’s zoals GPT 5.2.
Op maat van een doelgerichte case
De aanpak van Taalas vereist dus dat klanten een business case bedenken die gekoppeld is één een model, waarbij dat model adequaat blijft tot de investering is afgeschreven. Dat is niet zo gek: grote LLM’s stelen de show door hun capaciteiten, maar operationele efficiëntiewinst komt van gerichte toepassingen.
lees ook
Nvidia introduceert Rubin en Vera: 5 keer meer inferentie dan Blackwell en eigen CPU
Indien een LLM slim genoeg is om de functionaliteit van een veelgebruikte agent in een goed gedefinieerde workflow te ondersteunen, is er niet zo veel reden om daaraan te sleutelen. Voor een volwassen en doordachte business case biedt de aanpak van Taalas een manier om inferentie met maximale efficiëntie en dus minimale kost in te bakken.
Ook voor robotica is de hardwaregebaseerde AI-chip potentieel heel interessant. De zuinigere accelerator met verwaarloosbare latency opent nieuwe deuren. Denk niet alleen aan exotische machines, maar bijvoorbeeld ook aan toekomstige auto’s.
Op naar een groter model
Eer het zover is, moet Taalas nog wel wat werk verrichten. De Taalas HC1 is een demonstratieproduct. In de loop van dit jaar wil Taalas een tweede demonstratiechip lanceren, gebaseerd op de HC1 maar met een iets groter model ingebakken.
Daarna volgt het grote werk. In een tweede generatie van zijn platform (HC2) plant Taalas om de technologie los te laten op een frontier-model: een modern en groot LLM van het niveau van de GPT 5.2’s en Opus 4.6’en van deze wereld.
Doorbraak
De cijfers liegen er niet om: Taalas heeft met een beperkt team, beperkte tijd en beperkte middelen succesvol aangetoond dat er een enorme meerwaarde te vinden is in hardwarematig gecodeerde LLM’s. Dergelijke brein-chips blinken uit in efficiëntie, zowel wat productie als gebruik betreft. Dat is met de Taalas HC1 en de bijhorende chatbot-demo meteen duidelijk.
Of de aanpak in deze fase zal aanslaan, is nog afwachten. Taalas zelf heeft nog werk om te demonstreren dat ook meer capabele modellen op deze manier functioneren. Omgekeerd moet de markt voldoende volwassen worden om business cases met vertrouwen aan één model te koppelen.
Hoe dan ook is de lancering van de Taalas HC1 een nieuwe belangrijke doorbraak in de verdere ontwikkeling en democratisering van AI.