
In de context van generatieve AI is er veel interesse in “chat with your data” toepassingen waarbij je vragen kunt stellen over bedrijfseigen informatie. Grote taalmodellen (LLM’s – Large Language Models) zoals GPT-4 zijn in staat om taalkundig correcte tekst te genereren. Standaard gebeurt dat op basis van de gegevens waarop ze getraind zijn. Die kennis is echter beperkt in de tijd; het taalmodel heeft geen kennis van meer recente gebeurtenissen en informatie. Men spreekt van een knowledge cut-off op een bepaalde datum.
Een taalmodel heeft ook geen toegang tot bedrijfseigen informatie. Om antwoorden te verkrijgen omtrent recentere gegevens of eigen gegevens, moeten deze op één of andere manier aangeleverd worden aan het taalmodel. Enter de Retrieval Augmented Generation (RAG) architectuur. Dit is een aanpak waarbij de prompt – dit is de input die men geeft aan het taalmodel – verrijkt wordt met de meest relevante stukken tekst uit een informatiebron. Op die manier kan het taalmodel toch antwoorden formuleren op basis van eigen informatiebronnen.

Een initiële basisversie van zo’n generatieve question answering toepassing is snel opgezet, maar de échte uitdaging zit in het bekomen van een zekere kwaliteit van de antwoorden.
Hieronder geven we een aantal technieken mee die de kwaliteit kunnen helpen verbeteren. Deze lijst is niet exhaustief, maar geeft in grote lijnen aan op welke vlakken er verbeteringen mogelijk zijn.
Ingestion fase
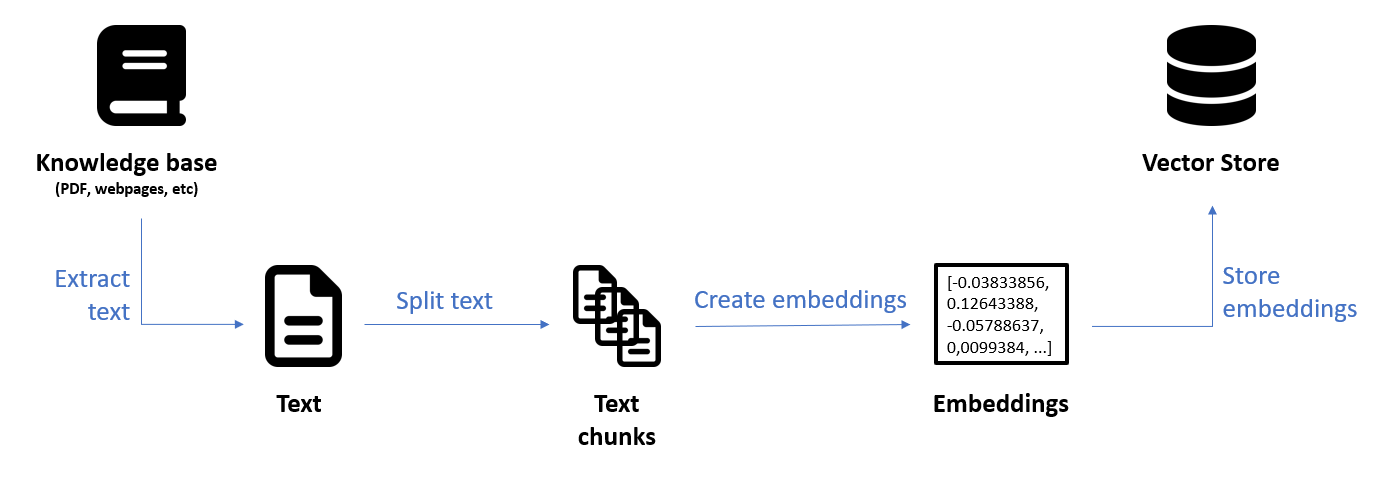
Ingestion is de voorbereidende fase waarin de originele gegevensbronnen (knowledge base) omgevormd worden en bijgehouden worden in een vector store index. Uit die vector store index kunnen dan in de uitvoeringsfase de meest relevante stukken tekst opgehaald worden (retrieval) om die mee te geven als context aan het taalmodel voor het genereren van het antwoord.

{kind=link}
Knowledge base en data extractie
De eerste stap in de ingestion pipeline is het extraheren van de tekst uit de knowledge base. De kwaliteit van de gegevens die uiteindelijk in de index zullen belanden, bepaalt in hoge mate de kwaliteit van het uiteindelijk antwoord. Daarom is het nuttig om niet-relevante informatie weg te filteren en de knowledge base eventueel uit te breiden met bijkomende bronnen die wél relevante informatie bevatten.
Chunking
Een volgende stap is het opsplitsen van de originele tekst in kleinere delen (chunks) zodat kleine, coherente stukken tekst kunnen opgezocht worden die relevant zijn voor de inputvraag en als context kunnen meegegeven worden aan het taalmodel voor het genereren van een antwoord.
Dat opsplitsen (chunking) kan op verschillende manieren gebeuren. De meest eenvoudige techniek is om te splitsen volgens een vast aantal characters. Een testomgeving zoals de open source LangChain Text Splitter Playground laat toe om te experimenteren met de grootte (chunk size) en de eventuele overlap tussen de stukken tekst (chunk overlap). Te grote chunks kunnen irrelevante informatie bevatten en te kleine chunks mogelijk te weinig.
Nog beter dan opsplitsen volgens een vast aantal characters is om de tekst op te splitsen op basis van de structuur. Een minimum hierbij is om zinnen of paragrafen in zijn geheel te behouden. Dat kan bijvoorbeeld met de RecursiveCharacterTextSplitter van LangChain. We kunnen daarenboven ook rekening houden met de structuur van documenten. Een voorbeeld hiervan is de HTMLHeaderTextSplitter die toelaat om een HTML document op te splitsen op basis van bepaalde header elementen (h1, h2, etc). Zo zijn de chunks meer één coherent geheel.
Finetunen van het embedding model
De laatste stap voor het creëren van de index is het aanmaken van vector embeddings op basis van de tekst chunks. Een embedding model zet de chunks en de inputvraag om naar embeddings. Dat zijn multi-dimensionele vectoren die de semantiek van de tekst capteren. Dat laat toe om die stukken tekst op te zoeken die semantisch het meest gerelateerd zijn aan de inputvraag.
Het is duidelijk dat het embedding model een belangrijke bijdrage kan leveren aan de kwaliteit van het vraag-antwoordsysteem. De keuze van het embeddings model moet gealigneerd zijn met de noden van het project, zoals ondersteuning voor meertalige content. Eventueel kan het embedding model gefinetuned worden om domein-eigen termen beter te capteren. Dat vereist echter een zekere effort.
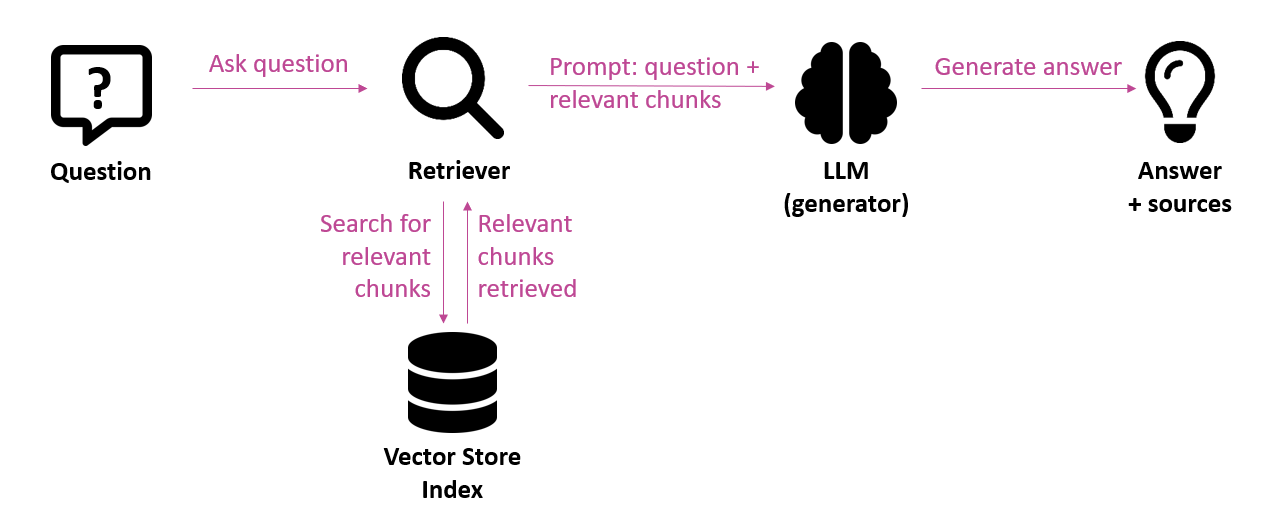
Uitvoeringsfase
De uitvoeringsfase is de fase waarbij de inputvraag van de gebruiker verwerkt wordt en via de retrieval en generation stappen uiteindelijk leidt tot een gegenereerd antwoord. Ook en vooral in deze fase zijn er een aantal technieken die de kwaliteit van het eindresultaat gunstig kunnen beïnvloeden.
Hybrid search
Eenmaal de content voorbereid is en de index opgebouwd werd, is de vraag hoe we díe stukken tekst kunnen vinden die het meest relevant zijn voor de inputvraag. De meest eenvoudige techniek is semantic search: voor de gegeven inputvraag zoeken we de k “dichtste”, meest semantisch gerelateerde, stukken tekst in de vectorruimte.
Hybrid search is een combinatie van een tekstuele zoekopdracht (lexical search of keyword search) en semantic search op basis van een index die zowel gewone tekst bevat als vector embeddings.
Het voordeel van vector search is dat informatie kan teruggevonden worden die semantisch verband houdt met de inputvraag, zelfs als er geen keyword matches zijn. Zo kan de vraag “hoe oud moet ik zijn voor een studentenjob” toch gelinkt worden aan een fragment als “de minimumleeftijd is 16 jaar”. Het voordeel van lexical search is dan weer de precisie door het exact matchen van woorden.
Beide zoekopdrachten – lexicaal en semantisch – worden in parallel uitgevoerd en de resultaten van beide zoekopdrachten worden gecombineerd in één lijst van resultaten. Die resultaten worden vervolgens opnieuw gerangschikt (re-ranking) volgens hun relevantie ten opzichte van de inputvraag. Deze belangrijke stap zorgt ervoor dat de meest relevante resultaten teruggegeven worden, los van het feit of ze nu het resultaat zijn van een semantische zoekopdracht of lexicale zoekopdracht. Een dergelijke re-ranking stap is in het bijzonder nuttig bij retrieval technieken die een uitgebreide of diverse lijst van documenten teruggeven, zoals query expansion (zie hieronder).
Technieken met betrekking tot de inputvraag
Een aantal technieken zijn erop gericht om de input voor de retriever uit te breiden (query expansion) om de resultaten van de retrieval te verbeteren. De retrieval kan immers verschillende resultaten opleveren door subtiele wijzigingen in de inputvraag of indien de embeddings de semantiek van de gegevens niet goed capteren.
Multi-query retriever – Deze eerste techniek maakt gebruik van een LLM om op basis van de originele inputvraag bijkomende vragen te genereren, als varianten op de originele inputvraag. Voor elk van die vragen (inclusief de originele vraag) wordt een retrieval uitgevoerd van de relevante documenten. Uiteindelijk wordt de combinatie van alle resultaten teruggeven. Op die manier wordt getracht om een rijkere, diversere set van resultaten te bekomen bij de retrieval.
HyDE (Hypothetical Document Embeddings) is een methode waarbij door middel van een extra LLM oproep een hypothetisch antwoord gegenereerd wordt voor de gegeven inputvraag. Zowel dat hypothetisch antwoord als de originele inputvraag dienen dan als input voor de retrieval. De onderliggende gedachte is dat het hypothetische antwoord dichter bij de relevante documenten kan liggen in de embedding space, in vergelijking met de inputvraag.
Sub-queries – Een complexe of samengestelde inputvraag kan opgesplitst worden in meerdere eenvoudigere vragen (sub-queries). Dat kan uiteindelijk leiden tot meer relevante antwoorden omdat elke deelvraag afzonderlijk kan worden behandeld.
Query re-writing – Tenslotte kunnen lange vragen door een LLM samengevat worden tot de essentie (re-writing), wat de kwaliteit van de retrieval ten goede kan komen.
Merk op dat de bovenstaande technieken gebruik maken van een LLM en als gevolg een hogere totale kost kunnen hebben. Het finale antwoord kan ook langer op zich laten wachten door het uitvoeren van de extra LLM oproepen.
Verrijken van de context
Het idee van onderstaande technieken is om meer context mee te geven aan het taalmodel (zie LLM generator stap in figuur 1) dan enkel de kleine chunks op zich die we bekomen tijdens de retrieval.
Sentence window retriever – Bij deze techniek wordt initieel een specifieke zin (sentence) opgehaald die het meest relevant is voor de inputvraag. Die zin wordt dan uitgebreid met een breder venster van zinnen vóór en na de zin in kwestie. Zo kan meer context meegegeven worden aan het taalmodel voor het genereren van een antwoord, wat uiteindelijk tot een beter antwoord kan leiden.
Auto-merging retriever (of Parent document retriever) – Hier wordt elke chunk initieel opgesplitst in een hiërarchische structuur van een parent node en leaf nodes. Tijdens de retrieval worden de meest relevante leaf nodes gezocht. Als een bepaald aantal van de leaf nodes van een parent node matchen met de inputvraag, dan wordt een merging uitgevoerd van de kleinere leaf nodes in de grotere parent node en wordt de volledige parent node meegegeven als context aan het taalmodel.
Post-processing
Na de retrieval stap, maar vóór het aanroepen van het taalmodel voor het genereren van het antwoord, kan de lijst van opgehaalde documenten nog bijgewerkt worden om de kwaliteit van het antwoord positief te beïnvloeden.
Re-ranking – Het kan nuttig zijn om de opgehaalde documenten opnieuw te ordenen op basis van relevantie, met de hulp van een model. Dit is een stap die in het bijzonder nuttig is bij retrieval technieken die een uitgebreide of diverse lijst van documenten teruggeven, zoals multi-query retrieval.
Compression – Gewoon maar méér context aanleveren uit het idee dat “het antwoord er wel ergens zal instaan” doet geen goed aan de kwaliteit van het antwoord. Het taalmodel krijgt het moeilijker om de echt relevante informatie terug te vinden in de context. Daarom kan het nuttig zijn om redundante en overtollige informatie uit de opgehaalde documenten te halen.
Prompt engineering en finetuning van het taalmodel
Waar de vorige technieken zich toeleggen op het optimaliseren van het aanleveren van een optimale context aan het taalmodel, zijn er ook technieken die gericht zijn op de manier waarop het model te werk moet gaan. Prompt engineering is de kunst om de juiste instructies te geven aan het taalmodel. Few-shot prompting is een techniek waarbij één of enkele voorbeelden gegeven worden van de input en de output die verwacht wordt van het taalmodel.
Het taalmodel op zich kan gefinetuned worden zodat het bepaalde instructies beter opvolgt of beter omgaat met bedrijfseigen terminologie. Dit vereist echter een zekere effort en is duidelijk geen laaghangend fruit.
Conclusie
Er zijn heel wat technieken die kunnen helpen om de kwaliteit van de antwoorden in een generatief vraag-antwoordsysteem te verbeteren. In dit artikel hebben we er slechts enkele van besproken. In onze ervaring levert een hybride search al een significante verbetering op van de accuraatheid van de antwoorden. Andere technieken kunnen zeker ook hun nut bewijzen, afhankelijk van de specifieke noden van het project; er is geen “one-size-fits-all” oplossing.
Zelfs indien we finaal een hoge kwaliteit bekomen, kunnen er toch nog fouten opduiken en moeten we hiermee rekening houden, zowel op vlak van verwachtingsbeheer als op juridisch vlak. Zo is een melding dat het antwoord gegenereerd werd door AI onontbeerlijk en moet de eindgebruiker zich hiervan bewust zijn. Feedback van eindgebruikers is een goede manier om zicht te krijgen op de kwaliteit van het systeem en om voortdurend te kunnen bijsturen waar nodig.
Dit is een ingezonden bijdrage van Bert Vanhalst, IT consultant bij Smals Research. Dit artikel werd geschreven in eigen naam en neemt geen standpunt in namens Smals. Interesse om bij Smals te werken? Neem dan een kijkje naar het huidige uitgebreide jobaanbod.
{kind=link}